










 AI智能应用开发
AI智能应用开发 AI大模型开发(Python)
AI大模型开发(Python) AI鸿蒙开发
AI鸿蒙开发 AI嵌入式+机器人开发
AI嵌入式+机器人开发 AI运维
AI运维 AI测试
AI测试 跨境电商运营
跨境电商运营 AI设计
AI设计 AI视频创作与直播运营
AI视频创作与直播运营 微短剧拍摄剪辑
微短剧拍摄剪辑 C/C++
C/C++ 狂野架构师
狂野架构师


如果leader崩溃,Kafka怎样重新选举?
更新时间:2021年10月29日14时15分 来源:传智教育 浏览次数:

leader对于消息的写入以及读取是非常关键的,此时有两个疑问:
1. Kafka如何确定某个partition是leader、哪个partition是follower呢?
2. 某个leader崩溃了,如何快速确定另外一个leader呢?因为Kafka的吞吐量很高、延迟很低,所以选举leader必须非常快。
如果leader崩溃,Kafka会如何?
使用Kafka Eagle找到某个partition的leader,再找到leader所在的broker。在Linux中强制杀掉该Kafka的进程,然后观察leader的情况。
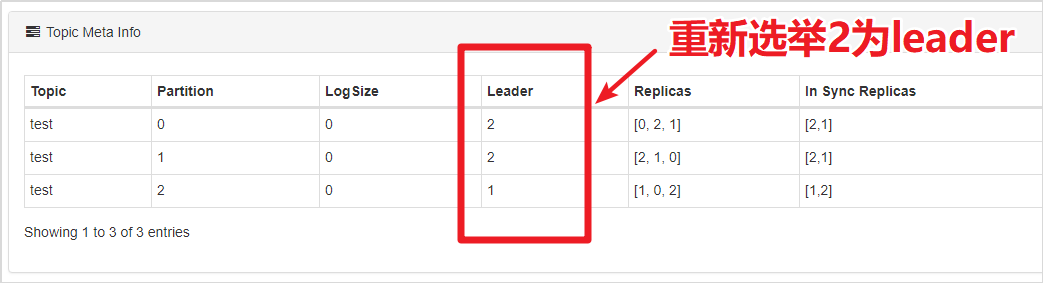
通过观察,我们发现,leader在崩溃后,Kafka又从其他的follower中快速选举出来了leader。
Controller介绍
l Kafka启动时,会在所有的broker中选择一个controller
l 前面leader和follower是针对partition,而controller是针对broker的
l 创建topic、或者添加分区、修改副本数量之类的管理任务都是由controller完成的
l Kafka分区leader的选举,也是由controller决定的
Controller的选举
l 在Kafka集群启动的时候,每个broker都会尝试去ZooKeeper上注册成为Controller(ZK临时节点)
l 但只有一个竞争成功,其他的broker会注册该节点的监视器
l 一点该临时节点状态发生变化,就可以进行相应的处理
l Controller也是高可用的,一旦某个broker崩溃,其他的broker会重新注册为Controller
找到当前Kafka集群的controller
1. 点击Kafka Tools的「Tools」菜单,找到「ZooKeeper Brower...」
2. 点击左侧树形结构的controller节点,就可以查看到哪个broker是controller了。
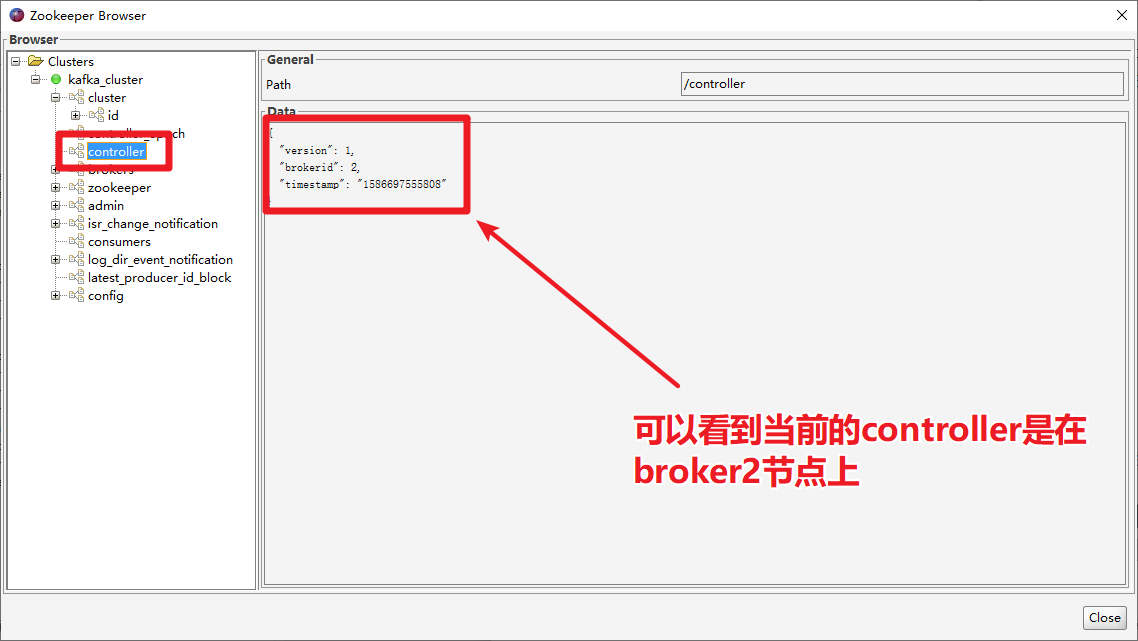
测试controller选举
通过kafka tools找到controller所在的broker对应的kafka进程,杀掉该进程,重新打开ZooKeeper brower,观察kafka是否能够选举出来新的Controller。
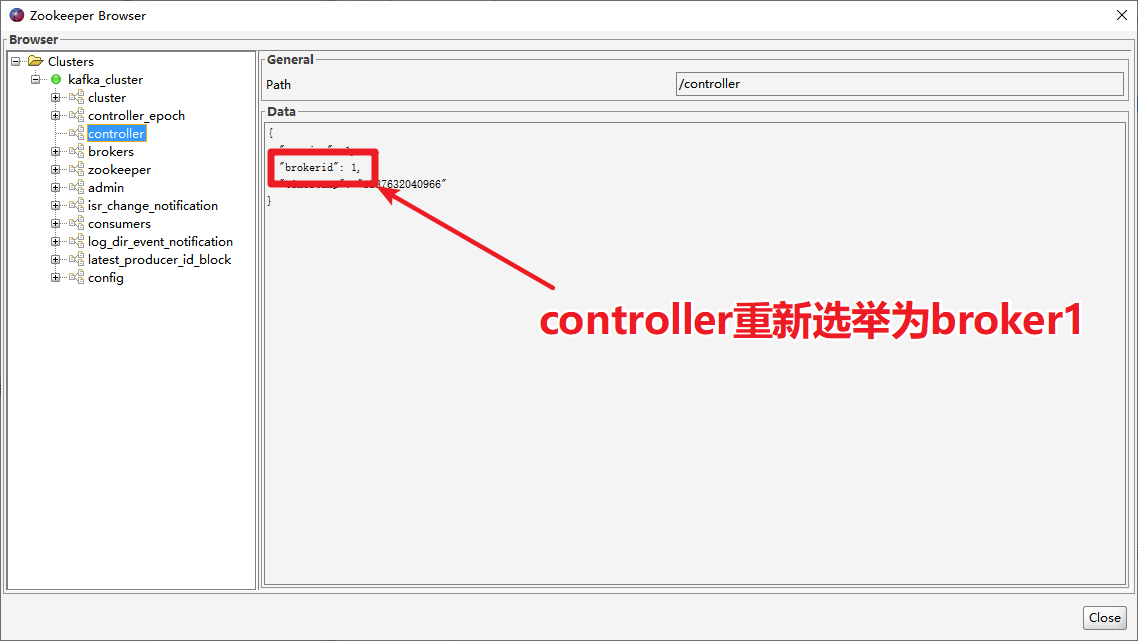
Controller选举partition leader
l 所有Partition的leader选举都由controller决定
l controller会将leader的改变直接通过RPC的方式通知需为此作出响应的Broker
l controller读取到当前分区的ISR,只要有一个Replica还幸存,就选择其中一个作为leader否则,则任意选这个一个Replica作为leader
l 如果该partition的所有Replica都已经宕机,则新的leader为-1
为什么不能通过ZK的方式来选举partition的leader?
l Kafka集群如果业务很多的情况下,会有很多的partition
l 假设某个broker宕机,就会出现很多的partiton都需要重新选举leader
l 如果使用zookeeper选举leader,会给zookeeper带来巨大的压力。所以,kafka中leader的选举不能使用ZK来实现。
猜你喜欢:
最新资讯




















江苏传智播客教育科技股份有限公司 版权所有Copyright 2006-2024 All
Rights Reserved
苏ICP备16007882号营业执照增值电信业务经营许可证出版物经营许可证 苏公网安备 32132202001156号
苏公网安备 32132202001156号
免费领取黑马程序员AI通道专属星级课程资料
